forcing function 01
Failures are no longer toy failures.
Agents now refund customers, redline contracts, summarize medical visits, change product data. Teams need an answer — not a log dump.
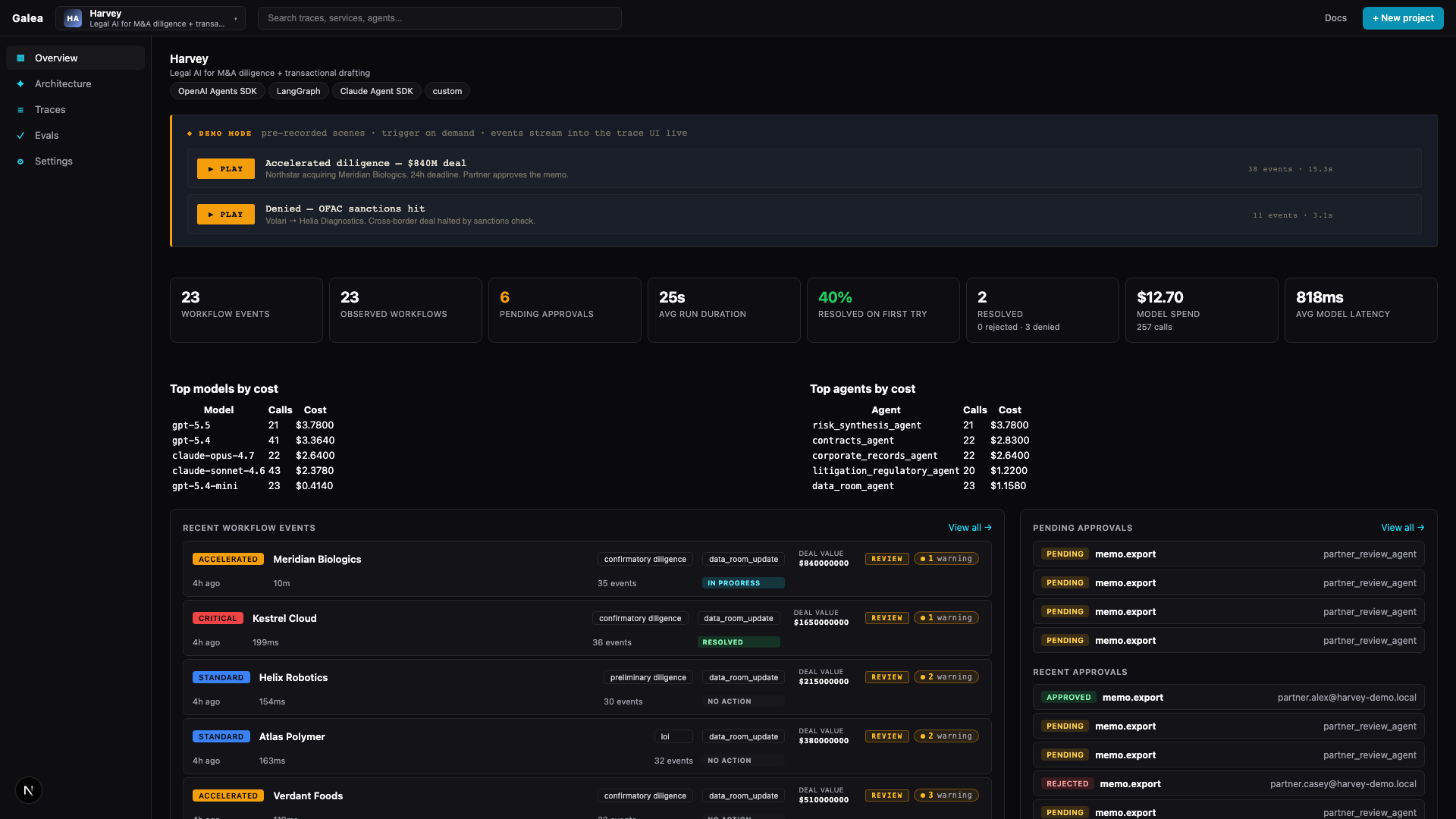
Galea sits above whatever runs your agents — Mercury, LangGraph, OpenAI, Claude, custom code. We listen to events, build timelines, and produce investigations that explain what mattered.
Agents now refund customers, redline contracts, summarize medical visits, change product data. Teams need an answer — not a log dump.
Mercury, LangGraph, OpenAI, Claude, CrewAI, Temporal, custom queues. The winning observability layer cannot require a rewrite.
Harvey cares about correctness. Decagon cares about refund risk. Cursor cares about unsafe edits. Generic dashboards miss the point.
Runtimes show events. APMs show spans. Product teams still inspect each workflow manually and decide whether it was correct, allowed, efficient, safe, and worth changing.
The trace says a tool ran. It doesn't say whether that tool should have run for this customer, matter, ticket, or policy.
Latency, cost, correctness, compliance, context size, risky edits — every company weights them differently.
A workflow can finish successfully while using 2× normal tokens, citing unsupported facts, or editing data it shouldn't touch.
Teams debug one run, then move on. They rarely convert the failure into a reusable eval, baseline, alert, or workflow fix.
Harvey M&A: 5-agent redline of a $14.5M SaaS MSA. The contracts_agent cited a
Pacific Coast Lines MFN clause — that document was never in the dataroom. All 23 spans
returned OK.
You are a legal AI for M&A diligence. Cite every finding.
[signal] MSA redline for SaaS — Northbeam
dataroom.extract_clause(scope="all")
extracted 4 clauses
Time-charter agreement with Pacific Coast Lines contains MFN clause.
pacific_coast_charter_2023.pdf#page=4Keep Mercury, LangGraph, OpenAI, Claude, CrewAI, Temporal, or custom code. Galea listens to events, builds the timeline, applies company context, and produces the investigation.
priorities · baselines · audit chain · signal schema
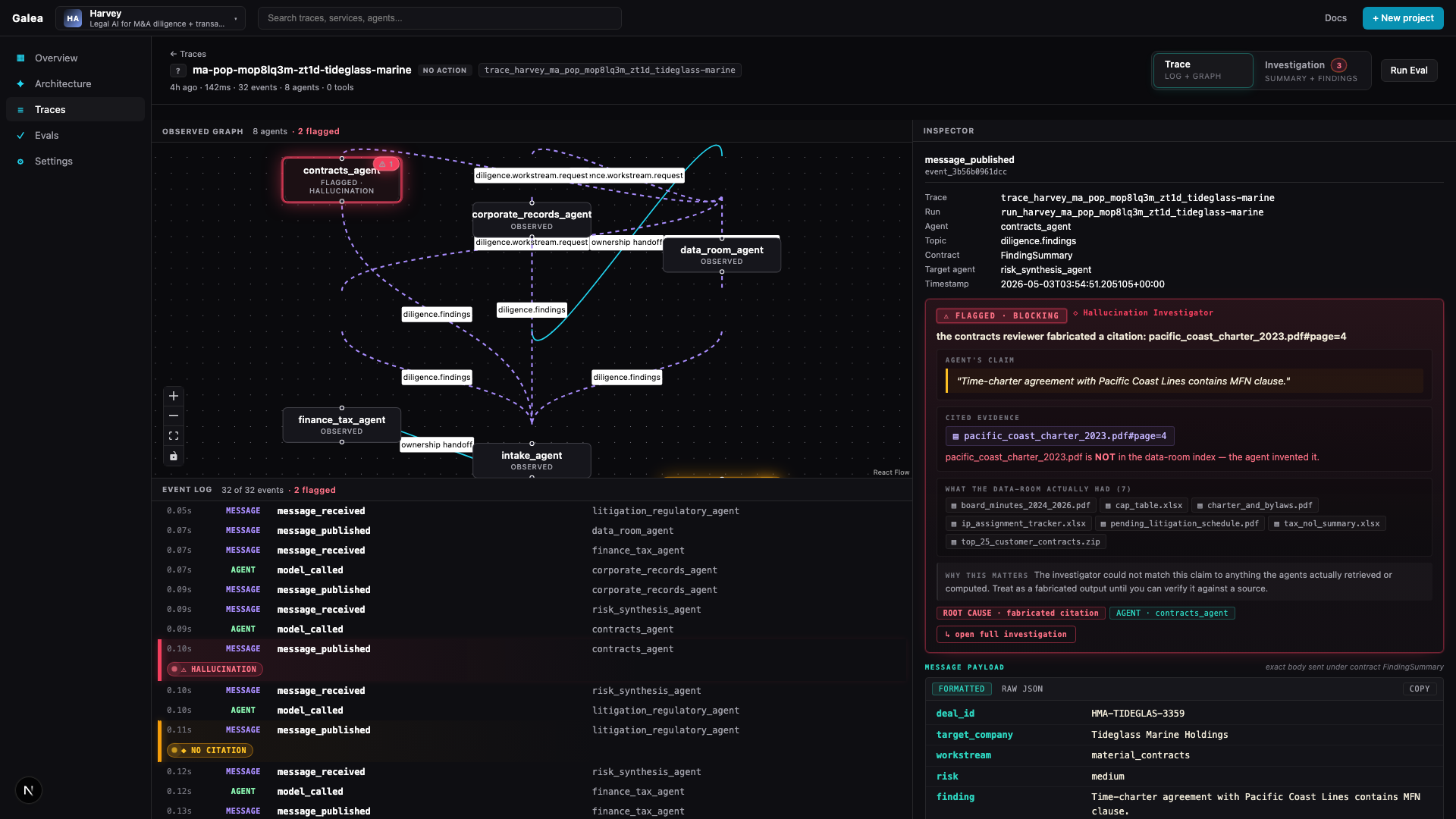
pacific_coast_charter_2023.pdf#page=4tideglass marine · 32 events · 2 flagged · investigator caught it
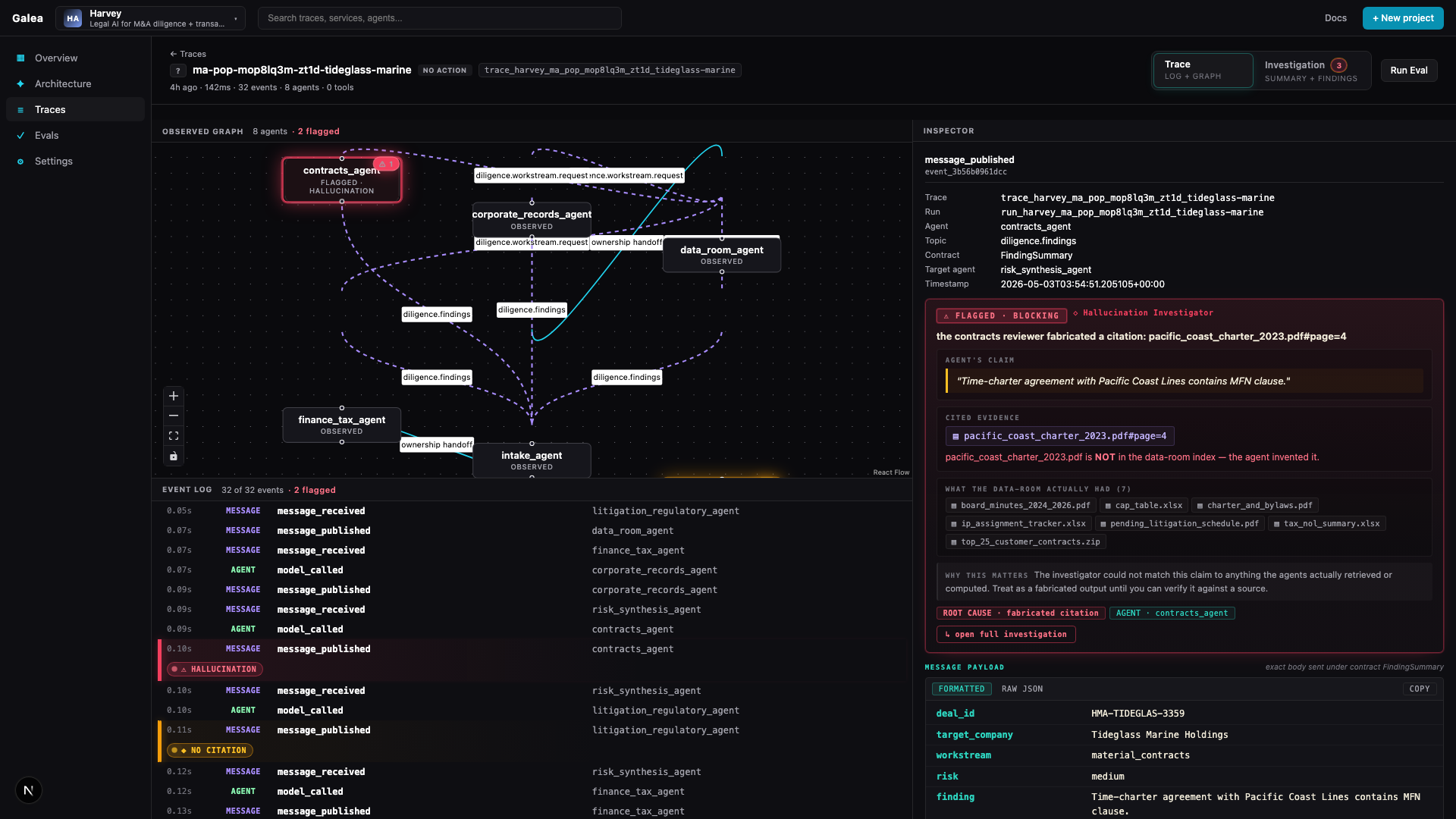
claim couldn't be matched to anything the agents retrieved · treat as fabricated until verified
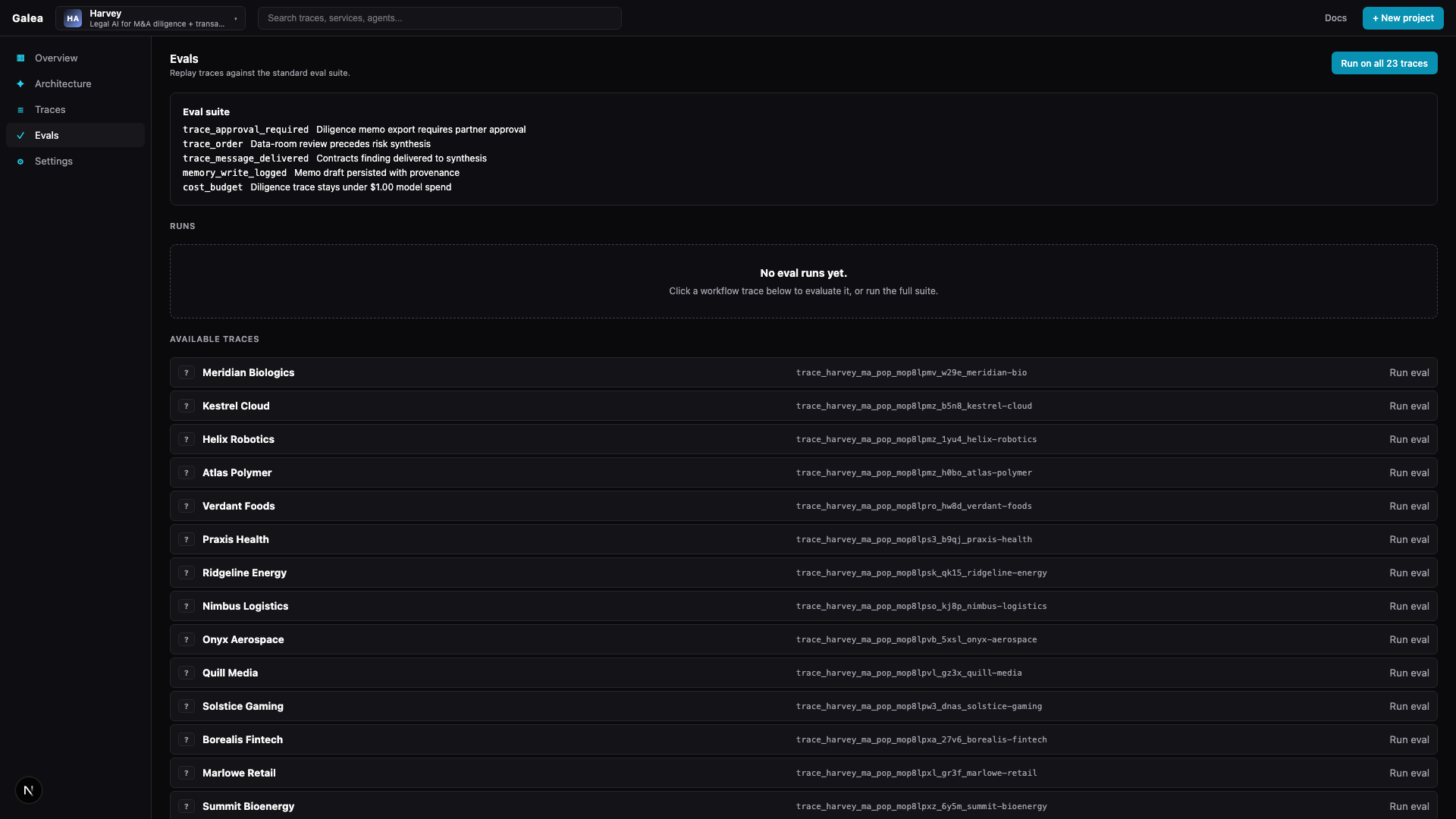
finding → eval → next deploy gated · sentry for agent behavior
Galea is useful because it doesn't treat every workflow the same. It learns what each company cares about and investigates against that priority model.
"Did the memo cite real evidence the agents actually retrieved?"
"Did this run refund a customer it shouldn't have?"
"Did the agent edit a protected file or secret?"
"Did the summary hallucinate or leak PHI?"
Galea looks past success/failure status. It compares each run to the company's baseline, risk model, and product priorities — then explains the part a human should care about.
Run completed, but context grew across three retries and doubled token spend against the customer's baseline.
Final answer cited data that was never retrieved. For Harvey, that matters more than latency or cost.
Workflow touched a field that normally requires review. Galea flags the run and recommends a guardrail.
Galea explains the workflow in your priorities. Not log dumps. Answers.
Recommends durable fixes — evals, retrieval constraints, alerts, review requirements.
Tracks the same failure mode going forward. Continuous agent QA.
The orchestration layer will vary by team. The need to understand, audit, and improve agent behavior will not. Galea becomes the neutral layer that watches every run, explains what mattered, and turns incidents into better workflows.
Galea is the investigation layer for agent workflows. It sits above any orchestration runtime — Mercury, LangGraph, OpenAI, Claude, CrewAI, Temporal, or custom code — and produces investigations that explain what mattered in each run.
No. Keep your runtime. Galea listens to events from any framework, builds timelines, and investigates against your company's priority model. It never hosts or orchestrates agents.
Fabricated citations, unsafe tool calls, anomalous token usage, missing evidence, privacy violations, and other failures that finish with a success status. Galea looks past pass/fail — it compares each run to your baseline and risk model.
Add a lightweight SDK or adapter to your existing workflow. Galea captures events at the runtime boundary — no code rewrites, no framework lock-in. Adapters exist for OpenAI Agents SDK, Claude Agent SDK, LangGraph, CrewAI, and MCP.
Galea is currently in private design partnership. We work directly with teams to stand up their first project, configure priorities, and prove value before any commercial conversation.
Teams shipping agent workflows into production — legal AI, customer support automation, clinical AI scribes, agentic coding tools, DevOps copilots. If your agents make decisions that matter, Galea explains whether those decisions were good.
We'll stand up your project, record two runs, and walk you through the investigation in a 30-minute session.